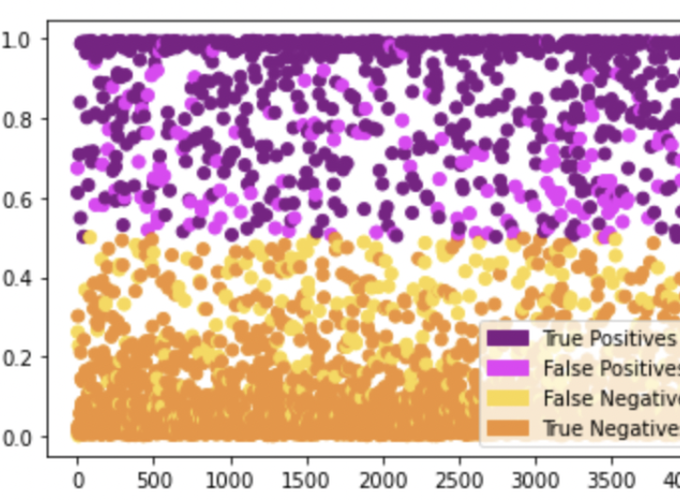
Confidence scores for each example in the test set, color-coded according to the confusion matrix of our model
MilaNLP at SemEval-2023 Task 10: Ensembling Domain-Adapted and Regularized Pretrained Language Models for Robust Sexism Detection
Abstract
We present the system proposed by the MilaNLP team for the Explainable Detection of Online Sexism (EDOS) shared task. We propose an ensemble modeling approach to combine different classifiers trained with domain adaptation objectives and standard fine-tuning.Our results show that the ensemble is more robust than individual models and that regularized models generate more “conservative” predictions, mitigating the effects of lexical overfitting.However, our error analysis also finds that many of the misclassified instances are debatable, raising questions about the objective annotatability of hate speech data.
Type